
Containerbasierte und klassische Webanwendungen im Vergleich - was eignet sich wann?
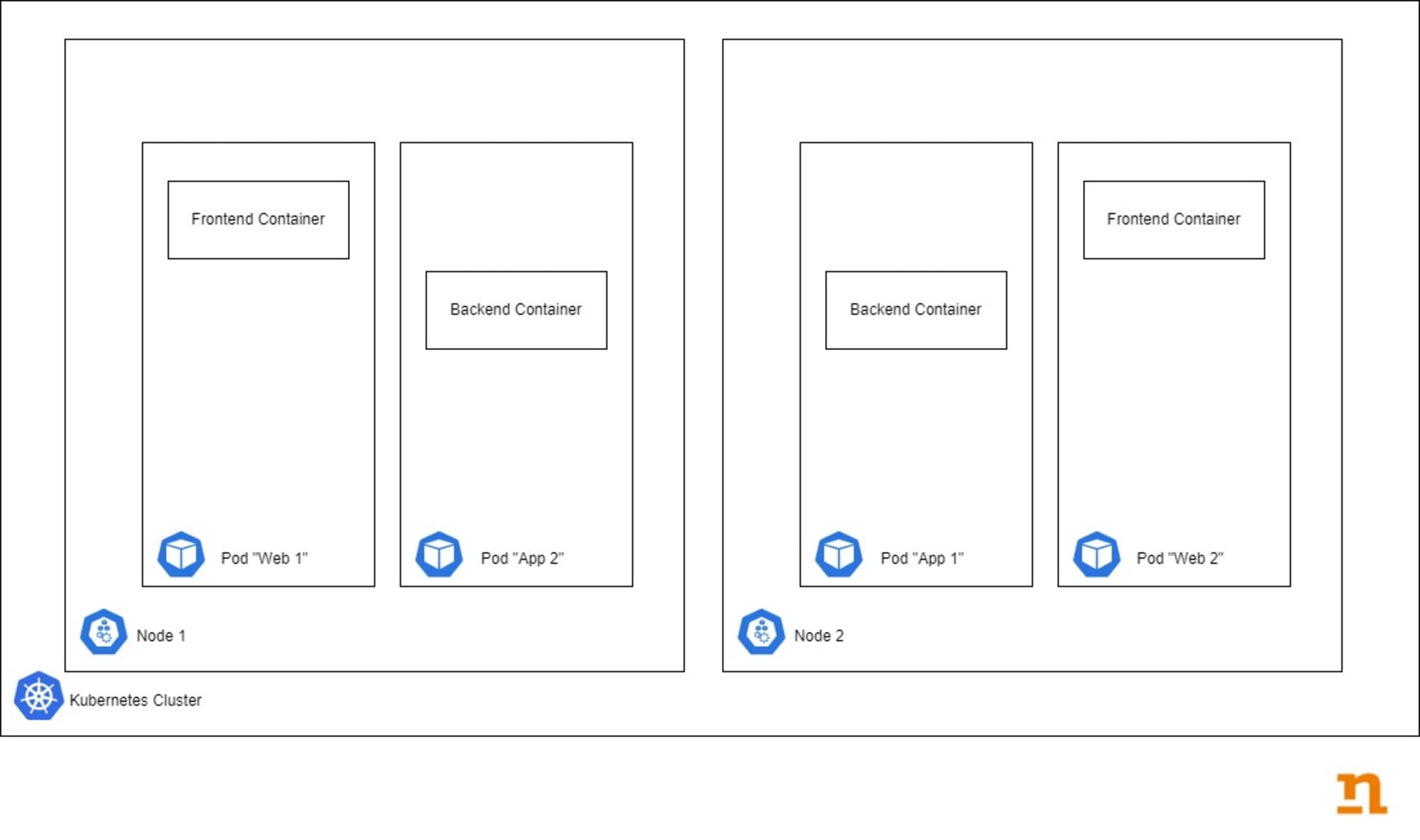
Aufbau einer containerbasierten Anwendung
Die Implementierung von containerbasierter Software unterscheidet sich - vereinfacht gesagt - nicht gross von "normaler Software". Der grosse Unterschied ist, wie die Software paketiert, auf dem Zielsystem gehostet und betrieben wird.
Die Software wird mit den benötigten Bibliotheken und Laufzeit-Abhängigkeiten in einen Container «paketiert». Dieser kann dann beispielsweise in einem Container-Verzeichnis («Container Registry») zentral abgelegt und daraus von anderen Systemen bezogen werden.
Verglichen mit der klassischen Virtualisierung ganzer Server mit VMWare oder HyperV laufen die Container direkt auf dem Betriebssystem vom Server und bringen kein eigenes mit. Damit sind sie schneller und benötigen weniger Ressourcen als die klassischen virtuellen Server.
Der Container wird auf den Server heruntergeladen und gestartet. Sie werden «isoliert» betrieben und können nicht auf andere Container oder das Betriebssystem vom Host-Server zugreifen.
Bei klassischer VM-basierten Lösungen würden bei zusätzlichem Ressourcenbedarf viel höhere Aufwände entstehen:
Neue Server (Hardware-basiert oder virtuell) kaufen oder mieten
Installation der virtuellen Maschine und benötigten Komponenten, ggf. Patches nachführen
Konfiguration von Netzwerk & Anpassung etwaiger Firewalls
Anpassung vom Load Balancer
Der Aufwand dafür ist deutlich höher. Schnelle Anpassungen bei vielen Besuchern sind nur verzögert möglich.
Wie unterscheidet sich das Deployment?

Der Weg der Software bis zur produktiven Umgebung sieht neu so aus:
Die Entwicklerin oder der Entwickler arbeitet auf seinem PC mit der Entwicklungsumgebung (hier Visual Studio). Die Software wird kompiliert und daraus ein Container erstellt.
Der Container wird auf der lokalen Umgebung (hier Docker Desktop) installiert und getestet.
Anschliessend wird der Quellcode ins Versionsverwaltungssystem git eingecheckt.
Diese Änderung wird von den Build Pipelines erkannt und daraus ein versionierter Container erstellt.
Nach dem erfolgreichen Ausführen der automatisierten Tests wird der Container im Container Verzeichnis («Container Registry») abgelegt.
Das Programm ArgoCD prüft regelmässig, ob neue Container bereitstehen, und installiert diese anschliessend auf den definierten Kubernetes Clustern oder Umgebungen (für Dev, Test, Release).
Das Aufspielen kann manuell erfolgen oder automatisiert basierend auf Branch-Namen oder Tags auf den Commits im git-Repository.
Auf der Betriebsumgebung des Kunden läuft es ähnlich ab:
Freigegebene produktive Versionen der Container werden manuell oder automatisch vom Container-Verzeichnis von Nexplore abgerufen.
Die Installation auf die verschiedenen Umgebungen wie Test, Pre-Prod / Quality und Produktion erfolgen nach den Vorgaben von Kunde und Betreiber – nach manueller Freigabe oder automatisch, wenn die neue Container-Version verfügbar ist.
Dieser Ablauf beinhaltet viele Schritte und Beteiligte. Das Wissen, die Erfahrung und auch die benötigten Tools müssen durchgängig vorhanden sein – sonst «klemmt» es im Ablauf.
Deswegen empfehlen wir, beim ersten Release viel Zeit einzuplanen, um die Schritte vorab genau zu spezifizieren, zu testen und bei Bedarf anzupassen. Sind die Prozesse und Systeme eingespielt, kann das Release dann auf Wunsch automatisch, ohne manuelle Arbeiten und Verzögerungen, durchgeführt werden.
Das Deployment dauert dann nicht mehr Tage und benötigt viele Experten aus dem IT-Betriebsteam, sondern wird beispielsweise automatisch in Minuten von Nexplore auf der Testumgebung beim Betreiber eingespielt.
Verwendung eines Mono-Repositories
Die umfangreiche Konfiguration aus Programmcode, Infrastrukturcode und Konfigurationsdateien muss sehr gut verwaltet werden.
Dafür hat sich das Konzept des «Mono-Repositories» durchgesetzt:
Alle Artefakte wie Programmcode und Konfigurationsdateien werden zentral in einem Verzeichnis (das sogenannte «Mono Repository») abgelegt und versioniert. Änderungen werden mittels «Pull Request» im 4-Augen-Prinzip geprüft und anschliessend übernommen. Bei Softwareprojekten ist diese Praxis seit Jahrzehnten ein Pfeiler des Erfolgs.
Enthalten sind in unseren Projekten beispielsweise:
Programmcode vom Frontend (Web-Applikation, beispielsweise in der Programmiersprache TypeScript oder JavaScript)
Programmcode vom Backend (Business-Logik und Schnittstellen, beispielsweise in der Programmiersprache C# für die .NET-Plattform von Microsoft)
Konfigurationsdateien fürs Erstellen der Docker Container
Konfigurationsdateien für die Infrastruktur der Container im Kubernetes Cluster («Helm-Charts»)
Skripte und Konfigurationsdateien fürs Erstellen der Container und anderer Artefakte sowie fürs Aufspielen der Container
Weitere Dateien beispielsweise für Übersetzung
In unseren Projekten hat sich das Tool NX bewährt. Es erstellt und orchestriert die verschiedenen Artefakte von Frontend-, Backend bis hin zu Docker Images, Helm-Charts und Abhängigkeiten - bereits auf den Entwickler-Workstations und Build Pipelines. Damit ist der Ablauf auf den Umgebungen gleich, was sehr vorteilhaft ist.
Was ist der Zusammenhang zwischen einem Container und einem Microservice?
Ein Container ist eine Laufzeitumgebung für eine Anwendung.
Ein Microservice stellt eine bestimmte Funktionalität mit einer definierten Schnittstelle bereit. Es wird als eigenständiges Modul entwickelt. Abhängigkeiten zu anderen Microservices werden durch definierte Schnittstellen abgesichert.
Eine Anwendung, die auf einer Microservice-Architektur basiert, hat ein oder mehrere Frontends und verschiedene Microservice-Backends.
Der Vorteil ist, dass die verschiedenen Microservices unabhängig entwickelt und im Betrieb skaliert werden können. Ist die Last für den Microservice zur Report-Generierung sehr hoch, können beispielsweise neue Instanzen des zugehörigen Containers hochgefahren werden.
Für grosse und sehr komplexe Applikationen, mit verschiedensten Modulen und Fachdomänen, ist diese Architektur gut geeignet.
Für eine «kleine» Web-Applikation ist die Verwendung von Microservices aber meist «overkill» - die Vorteile können nicht genutzt werden, Entwicklung und Betrieb sind viel aufwändiger.
So kann es sinnvoll sein, Frontend und Backend gemeinsam im gleichen Container laufen zu lassen. Diese «monolithische» Architektur bringt die Vorteile der Containerisierung auch für einfachere Applikationen.
Migration einer bestehender Applikation
Klassisch entwickelte Applikationen lassen sich auch schrittweise «containerisieren». Das ist besonders dann sinnvoll, wenn bereits hohe Investitionen getätigt wurden und die Software langfristig weiter genutzt werden soll.
Weitere Informationen sind im Blog Post «Migration von Legacy Applikationen» beschrieben.
Herausforderungen
Die grössten Herausforderungen sind die erhöhte Komplexität und der grössere Aufwand:
Die initiale Installation mit dem Aufbau eines Kubernetes Clusters und den benötigten Ressourcen, Helm-Charts und co ist aufwändiger als eine VM hochzufahren und die Webapplikation zu installieren.
Mit den vielen Komponenten und Modulen erhöht sich die Komplexität deutlich. Es braucht mehr Fachwissen, um das Gesamtsystem entwerfen und betreiben zu können.
Monitoring und Logging der verteilten Applikation ist deutlich aufwändiger.
Bei der Fehlersuche müssen die Informationen aus den verschiedenen Containern gesammelt werden – ein zentrales Logging-System ist dazu essenziell.
Bildnachweis: Photo by Growtika on Unsplash




