

Microsoft Fabric im Fokus: Implementation einer Datenpipeline

Szenario in der Praxis
Durch die Datenpipeline
Ein Data Lake oder Lakehouse, sowie auch ein klassisches DWH, gliedert sich üblicherweise in die drei Ebenen Bronze, Silver und Gold, auch Medallion Architecture genannt. Auf Databricks und Microsoft ist dieses Architekturprinzip ausführlich erklärt. Databricks geht zudem darauf ein, weshalb heutzutage im Lakehouse-Kontext oft von ELT- statt ETL-Prozessen die Rede ist (und wieso dies deshalb auch hier zutrifft).
Entsprechend der drei Schichten dieser Medallion Architecture wird der Lade- und Transformationsprozess für dieses Szenario gestaltet. Die Data Factory bzw. eine Data Pipeline orchestriert dabei den Datenfluss vom Bronze zum Silver und danach zum Gold Layer.
Für jedes der drei Datensets werden separate Kopieraktivitäten und Notebooks erstellt. Damit können die Ladevorgänge bis zum Silver Layer pro Quelle parallel gestartet werden. Nur wenn diese separaten Prozesse erfolgreich durchlaufen, wird der Gold Layer befüllt. Als letzter Schritt wird bei erfolgreichem Abschluss der gesamten Pipeline eine Meldung in einem Teams-Kanal abgesetzt. Das Verhalten bei Fehlern wird einfachheitshalber für diesen Blogpost nicht implementiert.
1) Beladen des Bronze Layer mit Copy Activity
Die gezippten Textdateien von datasets.imdbws.com laden und im Lakehouse nach Jahr/Monat/Tag ablegen.
2) Beladen des Silver Layer mit Notebooks und PySpark
Rohdaten entpacken und als benutzerfreundlichere Parquet Files sowie als Delta Tables speichern.
Kleinere Transformationen, wie die Anpassung von Datentypen oder Löschen von ungültigen Zeilen, ausführen, um validierte und vertrauenswürdige Daten bereitzustellen.
Die Daten sind nach der dritten Normalform modelliert (alternativ ist auch Data Vault denkbar).
3) Beladen des Gold Layer mit Notebooks und SQL
In diesem Layer werden domänenspezifische Datenmodelle und Data Marts für Analytics und Reporting bereitgestellt.
Der Modellierungsansatz ist üblicherweise ein dimensionales Datenmodell nach Kimball, was hier aber nicht umgesetzt wird. Da die drei geladenen IMDb-Datensets die gleiche Granularität aufweisen (eine Zeile ist ein Titel), werden sie nur zu einem grossen Set zusammengeführt.
Es interessieren nur Filme und Serien im engeren Sinne und solche, die nicht allzu obskur sind. Deshalb gelten folgende Filterkriterien: keine Adult-Filme, Rating > 0, Dauer > 0, Votes > 0, nur Titles vom Typ Film, Serie, Short o.ä. (keine Videospiele o.ä). Von den 10.5 Millionen Records bleiben danach noch ca. 975k übrig.
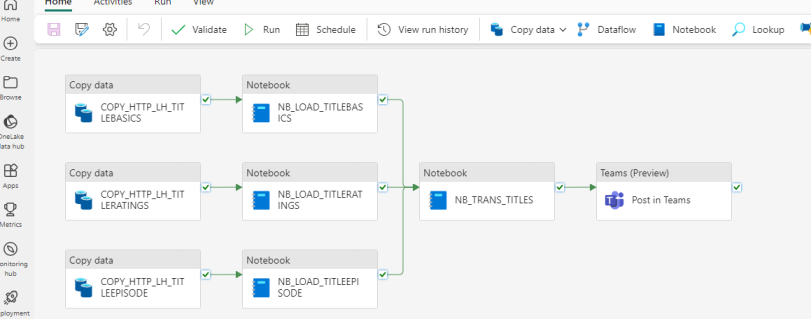 Übersicht über die Data Pipeline: Jede Quelle wird separat und parallel geladen.
Übersicht über die Data Pipeline: Jede Quelle wird separat und parallel geladen.
 Übersicht über die Delta Tables und Ordnerstruktur im Lakehouse.
Übersicht über die Delta Tables und Ordnerstruktur im Lakehouse.
 Ein Ausschnitt eines Notebooks mit PySpark-Code.
Ein Ausschnitt eines Notebooks mit PySpark-Code.
Unsere Data & AI Angebote

IMDb-Daten mit Power BI visualisieren
Fazit: Fabric bietet Flexibilität in der Datenverarbeitung und im Reporting
In dieser zweiteiligen Serie wurden die Kernkonzepte vorgestellt sowie ein praxisnaher ELT-Prozess umgesetzt, der mit in Fabric verfügbaren Technologien wie Data Factory, Notebooks und Power BI grosse Datenmengen von der Internet Movie Database verarbeitet und visualisiert. Es hat sich gezeigt, dass sich mit dem integrativen Ansatz von Fabric rasch und unkompliziert eine Datenpipeline realisieren lässt. Die verfügbaren Technologien bieten dabei Flexibilität für die Entwicklung. Mittels Dataflow Gen2 wäre auch eine Low-Code-Variante des hier verwendeten Prozesses denkbar gewesen.
Das Ziel war es, Ihnen mit diesem Beitrag wertvolle Einblicke in die Möglichkeiten und Funktionsweise von Microsoft Fabric zu geben. Falls Sie mehr erfahren möchten oder Potenzial für Ihre Anforderungen sehen, stehen wir Ihnen gerne zur Verfügung.




.jpg)